deepmind携mamba华人作家推transformer革命之作,效用暴涨媲美llama 2,推理能效大幅碾压
线性RNN赢了?近日,谷歌DeepMind一口气推出两大新架构,在d基准测试中超越了Transformer。新架构不仅保证了高效的训练和推理速度,并且成功(Success)扩展到了14B。
Transformer又又又被挑战了!
这次的挑战者来自大名鼎鼎的谷歌DeepMind,并且一口气推出了两种新架构,——Hawk和Griffin。

论文地址:https://arxiv.org/abs/2402.19427
这种将门控线性RNN与局部注意力混合在一起的模型新架构的表现相当亮眼。
首先,同为线性RNN架构的Griffin,凭借着1/2的训练数据,在所有评测中全面优于之前大火的Mamba。
更重要的是,Griffin将模型成功(Success)扩展到了14B,做到了Mamba想做却没能做的事。
其次,面对基于Transformer架构的模型,Griffin则凭借着1/6的训练数据,打平甚至超越了同等参数量的Llama 2!

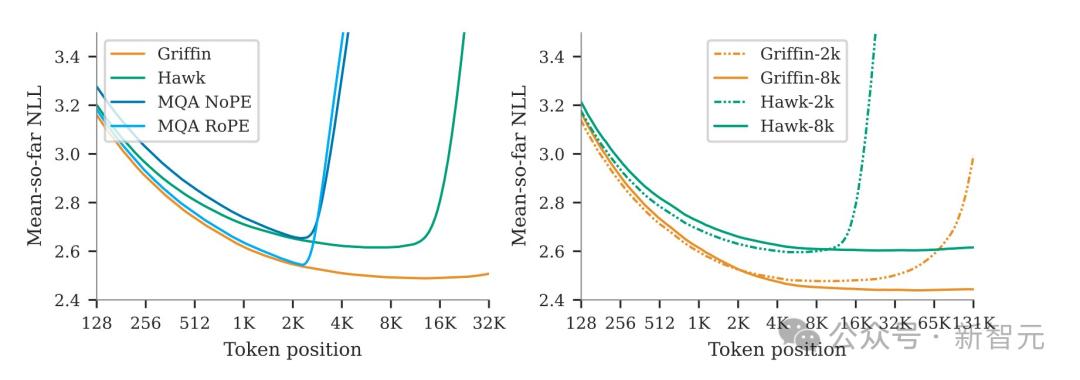
同时,模型能够利用(Use)很长的上下文来改进其预测,表明线性RNN的外推能力可以远远超出它们(They)训练的序列长度。
此外,团队还证明了这种组合构架保留了Transformer在合成任务上的许多功能,例如从长上下文中复制和检索token。

文章共同一作兴奋(Excited)地发推表示,Griffin这种新的模型构架效率非常高——它集合了线性RNN的所有的效率优势和Transformer的表现力(expressiveness)和规模化的优势。

推上给的配图也很有趣,还记得之前Mamba配图用自己的蟒蛇挑战变形金刚吗?这次Griffin(狮鹫)直接霸气占据C位,在赛道上领先。
小编莫名觉得Griffin对Mamba的伤害比较大,毕竟老鹰抓蛇......
不过这只是玩笑,因为我们(We)可以发现Mamba的作者Albert Gu也在这篇文章的作者之中——所以有可能天下的线性RNN都是一家人。
说回正题,虽然现在Transformer称霸江湖,但它平方级别的计算和存储开销对科研和工业界都造成了很大的压力(尽管喂饱了老黄......)。
大家在拼命做优化(比如Mamba另一位作者Tri Dao开发的FlashAttention系列)之余,也想另辟蹊径,于是就诞生了这些挑战Transformer的架构。
——如果真成了,就能跟「Attention Is All You Need」一样名留青史。
最近大火的几个著名研究都与线性RNN相关,比如RWKV、Mamba,以及我们(We)今天(Today)的Hawk和Griffin。

循环神经网站(RNN)在处理长序列数据时表现出色,因为它的推理开销是线性的,相比于Transformer有天然的计算和存储优势。
不过RNN系列在记忆和选择性提取信息方面相对于Transformer又有着原理上的劣势,所以在当前的这些任务上表现力不行。
另外,由于结构问题,训练大规模的RNN是非常困难的。
为此,研究人员提出了Hawk,一种采用了门控线性循环的RNN;以及Griffin,一个将门控线性反馈与局部注意力机制相结合的混合模型。
首先,研究人员提出了RG-LRU层,这是一个新颖的门控线性循环层,并围绕它设计了一个新的循环块来替代MQA。
接着研究人员以这个循环块为基础,构建了两个新模型:Hawk(将MLP与循环块混合使用),以及Griffin(将MLP与循环块和局部注意力混合使用)。

具体来说:
1. Hawk和Griffin模型在训练FLOPs和保留损失方面,展现出了与Transformer模型类似的幂律缩放关系,即使参数量达到7B以上也是如此(图1(a))。
2. 在所有模型规模上,Griffin的保留损失略低于强大的Transformer基线。
3. 对Hawk和Griffin模型在不同规模下使用300B token进行(Carry Out)了过训练。在一系列下游任务中,Hawk的表现超越了2倍token训练的Mamba模型,而Griffin则可以和6倍token训练的Llama-2相媲美。
4. 在TPU-v3上,Hawk和Griffin达到了与Transformers相当的训练效率。通过在Pallas中设计的RG-LRU层内核,研究人员在最大限度地减少内存传输的同时,克服了由于对角线RNN层的内存限制带来的挑战。
5. 在推理阶段,Hawk和Griffin的吞吐量显著高于MQA Transformers(图1(b)),并且在处理长序列时延迟更低。
6. Griffin在处理训练期间未见过的更长序列时,表现优于Transformers,同时还能高效地从训练数据中学习复制和检索任务。然而,如果不进行(Carry Out)微调,直接使用预训练模型进行(Carry Out)复制和精确检索任务的评估,Hawk和Griffin的表现则不如Transformers。

所有的模型都包含以下三大核心部分:(1) 一个残差块,(2) 一个MLP块,以及 (3)一个 时间混合块。
残差块和MLP块在所有模型中保持不变,而时间混合块则有三种不同的达成方式:
1. 全局多查询注意力(MQA);
2. 局部(滑动窗口)MQA;
3. 研究人员提出的循环块。
在循环块中,研究人员受线性循环单元的启发,提出了一种新型的循环层——真实门控线性循环单元(RG-LRU)。
如图2(a)所示,模型的全局结构由残差块定义,其设计灵感来源于预归一化的Transformers架构。
首先将输入序列进行(Carry Out)嵌入处理,然后让它通过
相关文章








- 赞(106) 踩(3) 阅读数(6076) 最新评论 查看所有评论
-
加载中......
- 发表评论
-